Dentre as inúmeras novidades que a Apple divulgou sobre a iOS 10 durante a WWDC em junho, uma das que menos chamou a atenção foi, curiosamente, uma das mais interessantes. Trata-se de uma tecnologia chamada “Differential Privacy” (algo como “privacidade diferencial”), que dá à Apple um trunfo monumental sobre o Google.
Resumidamente, a privacidade diferencial é um sistema matemático que permite a coleta de dados dos usuários sem comprometer a sua privacidade. Por meio dele, a Apple consegue oferecer a seus usuários o melhor de dois mundos: de um lado, sigilo absoluto com relação aos seus dados; por outro, aplicativos e programas que vão se adaptando aos padrões de uso dos usuários.
Bases de dados e privacidade
A maioria dos sistemas de inteligência artificial necessita de uma ampla base de dados para funcionar. Isso porque as inteligências artificiais vão sendo “treinadas” automaticamente ao longo do tempo, com apenas alguma intervenção de humanos. Pense no seu teclado do smartphone, por exemplo: se ele percebe que você costuam usar a palavra “busão”, ele passará a lhe recomendar essa palavra, mesmo que a princípio ele não a conheça.

Um exemplo melhor ainda é o Google Fotos. O aplicativo permite que os usuários armazenem na nuvem do Google um número ilimitado de fotos de celular, com resolução de até 16MP. Mas o que o Google ganha com isso? A resposta é: uma base de dados monstruosa com a qual treinar os seus sistemas de reconhecimento de rostos e objetos. Não é à toa que a busca do Google Fotos consegue reconhecer pessoas, animais, locais e até mesmo emojis: ela foi muito bem treinada para isso, e só deve ficar melhor com o tempo.
Há, obviamente, uma contrapartida bastante importante a essa coleta de dados justamente na questão da privacidade. Porque para lhe recomendar novas palavras, o Google precisa saber exatamente o que você escreve; para aprender a reconhecer as pessoas da sua foto, o Google precisa ver todas as suas fotos. Naturalmente, não há uma pessoa que fique lá no Google lendo suas mensagens ou olhando suas fotos, mas isso não muda o fato de que elas ficam armazenadas nos servidores da empresa, associadas ao seu nome.
Resposta da Apple
Isso cria uma situação particularmente complexa. Por um lado, é plenamente justificável que os usuários tenham receio de fornecer tantas informações tão pessoais assim a uma empresa. Mas por outro, o Google oferece ganhos bastante interessantes aos usuários que lhe confiam seus dados pessoais, em termos de funcionalidade.
Embora essa prática seja do Google, ela acaba se disseminando pelo mercado de serviços de tecnologia como um todo. Afinal, as empresas querem oferecer os melhores serviços possíveis a seus clientes; se isso exige a coleta de dados pessoais dos usuários – e se os usuários se mostram dispostos a abrir mão de sua privacidade em troca de mais recursos – então que assim seja.
É nesse contexto que a Apple declara que adotará a privacidade diferencial em algumas partes do iOS 10. Usando essa tecnologia, a empresa conseguirá continuar a oferecer os ganhos de funcionalidade decorrentes da coleta de dados dos usuários, mas sem os problemas de privacidade que essa coleta acarreta.

Como isso é possível?
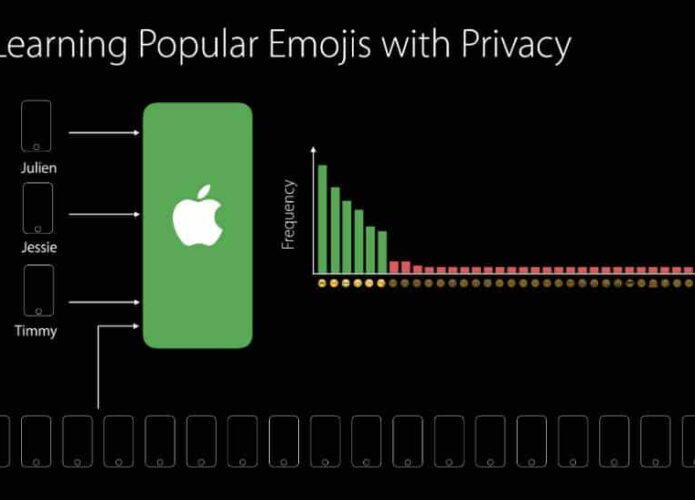
Em vez de simplesmente coletar os dados e utilizá-los para montar um “perfil” dos usuários, a técnica de privacidade diferencial manipula as informações de maneira muito mais complexas. Sem entrar muito nos detalhes matemáticos e estatísticos da tecnologia (sobre os quais é possível ler por meio deste link), ela envolve manipular os dados coletados de forma que eles fiquem quase irreconhecíveis, mas ainda consigam ser usados para tarefas de inteligência artificial.
Após serem coletados, os dados dos usuários são então “picados” em vários pedacinhos, embaralhados e misturados com outros dados completamente diferentes. Esse último processo é chamado de “injeção de ruído”. Dessa forma, o conjunto de dados resultantes após esse processo é bastante diferente dos dados inicialmente coletados.
Quando se pensa em um único usuário, esses dados embaralhados e misturados não têm muito valor. No entanto, quando esse procedimento é estendido a todos os usuários do iOS, por exemplo, alguns padrões começam a aparecer. Como os dados estão picados, embaralhados e misturados com ruído, é impossível saber qual é a contribuição exata de cada usuário para a base de dados. No entanto, é plenamente possível saber o que a base de usuários como um todo está fazendo.
Além disso, a empresa também pretende alternar a coleta de dados entre grupos de usuários diferentes. Para proteger a privacidade da base de dados como um todo, a Apple coletará dados primeiramente de um grupo de usuários. Quando as contribuições desses usuários chegarem a determinado ponto, a empresa excluirá a base de dados e começará novamente, com novos usuários.
Essa técnica traz duas vantagens à Apple. A primeira é garantir aos seus usuários que a segurança dos dados deles não será comprometida. A segunda é que, dessa maneira, ela não mantém bases de dados de seus usuários em seus servidores. Assim, se o FBI resolver brigar de novo com a empresa para que ela entregue dados de seus usuários, ela será simplesmente incapaz de responder, já que os dados sequer estarão armazenados.

Troca
Uma objeção que poderia ser feita é que esse sistema é muito menos eficiente do que a coleta direta de informações dos usuários. Além de dar muito mais trabalho para a empresa, ele também oferece recursos e recomendações menos precisas para os usuários – afinal, eles estão recebendo recomendações baseadas no conjunto de usuários, e não no seu próprio uso.
Tudo isso é verdade. Na privacidade diferencial, a eficiência dos resultados é inversamente proporcional ao sigilo dos dados que alimentam o sistema. Em outras palavras, quanto menos você quiser revelar sobre seus usuários, menos você receberá em troca em termos de recomendações e funcionalidades.
A Apple, no entanto, não parece se preocupar muito com isso. A postura da empresa é de se esforçar ao máximo para proteger o sigilo das informações de seus usuários. O mais provável, portanto, é que ela arrisque o menos possível revelar qualquer coisa, mesmo que isso signifique que suas inteligências artificiais vão demorar mais tempo para aprender.
Mas esse não é o único problema que o sistema da Apple tem. Talvez a falha mais grave dessa questão seja o fato de que a empresa não revele totalmente como está implementando essa tecnologia – o que impede que outras pessoas auditem seu método para avaliar se ele realmente é seguro ou não. Há que se considerar também que a Apple adotou essa medida porque permite coletar os dados de seus usuários em volume maior do que já fez até agora.
Essas questões, porém, importam relativamente pouco. Porque o que parece ser o verdadeiro objetivo da Apple com essa medida não é se igualar ao Google em termos de evolução da inteligência artificial, mas sim oferecer uma perspectiva diferente em um cenário tecnológico em que “privacidade” e “intimidade” são conceitos cada vez mais ausentes. Só de mostrar que “inteligência artificial” e “sigilo” não são incompatíveis, a empresa já conseguiu.